Abstract
-
Purpose
This study examines how the use of generative artificial intelligence (AI) in research may be interpreted and regulated under South Korea’s National Research and Development Innovation Act and its Enforcement Decree. It also evaluates how AI-assisted research practices challenge the conceptual boundaries of the statutory categories of research misconduct.
-
Methods
Through doctrinal legal analysis of Article 31 of the Act and Article 56 of the Enforcement Decree, common AI-assisted practices across the research cycle—design, literature review, data generation and analysis, manuscript writing, and the input of data into AI systems—were mapped to the Act’s misconduct taxonomy and related legal duties.
-
Results
Generative AI may plausibly implicate fabrication, falsification, plagiarism, and improper authorship (Article 31(1)1), as well as improper ownership of research and development outcomes and breaches of security measures (Article 31(1)3–4). The analysis further indicates that AI use destabilizes categorical boundaries, as individual outputs may simultaneously involve invented content, distorted interpretation, and unattributed reproduction. Numerous research-integrity risks arise from failures in research processes, including nondisclosure, inadequate verification, weak provenance tracking, and irreproducible analysis pipelines.
-
Conclusion
Legal and institutional responses should prioritize transparency across the research cycle and the development of auditable workflows, rather than focusing solely on sanctioning problematic outputs. Clear disclosure standards, verification obligations, reproducibility requirements, and stringent data-stewardship rules are necessary to address these emerging risks.
-
Key Words: Generative artificial intelligence; Scientific misconduct; National research and development innovation act; Research misconduct; Data security
INTRODUCTION
The rapid advancement of generative artificial intelligence (AI) has fundamentally transformed academic research. With developments in natural language processing, deep learning, and large language models (LLMs), generative AI is now widely used across the research process, including manuscript writing, literature review, data analysis, and research design. While it enhances productivity by efficiently synthesizing information and structuring arguments, it also introduces new risks to research reliability and ethical integrity.
Recent scholarship argues that generative AI disrupts the traditional “human-centered misconduct” framework underlying research ethics [
1,
2]. Because AI systems can generate fabricated data, statistics, images, and references that resemble authentic outputs, conventional misconduct—fabrication, falsification, and plagiarism—may occur in more covert and systematic ways. The non-deterministic and opaque nature of AI outputs, coupled with ambiguity in responsibility and accountability, further weakens reproducibility and verifiability. Existing peer review and plagiarism-detection mechanisms alone are insufficient to address these challenges [
3].
These concerns raise broader legal and institutional questions regarding how misconduct should be defined and regulated. In South Korea, national research and development (R&D) misconduct is governed by the National Research and Development Innovation Act (hereafter, “Innovation Act”). Article 31 of the Act and Article 56 of its Enforcement Decree classify misconduct into research misconduct and general misconduct, covering fabrication, falsification, plagiarism, improper authorship, improper ownership of research outcomes, misuse of R&D funds, and breaches of security measures. However, this framework was developed on the premise of traditional research practices and may not adequately reflect the novel ethical and legal issues posed by generative AI. To address this gap, this article proceeds in four steps, focusing on the nursing research context, where generative AI is increasingly used for literature synthesis, instrument development, survey-based studies, and clinical data interpretation. It first reviews the statutory categories of misconduct under the Innovation Act. Second, it defines generative AI and maps its use across key stages of nursing research. Third, it analyzes how AI-assisted practices may facilitate various forms of misconduct recognized under the Act. Finally, it examines the limits of the current statutory framework and discusses the legal and institutional implications for strengthening research integrity in nursing research.
METHODS
Definition of Misconduct Under the Innovation Act
The Innovation Act, which entered into force in 2021, expressly sets out research-ethics provisions, summarized in
Table 1 [
4]. Article 31 distinguishes between research misconduct—fabrication, falsification, plagiarism, improper authorship, and improper duplicate publication—and general misconduct, including misuse of R&D funds, improper ownership of R&D outcomes, breaches of security measures, and applying for or conducting R&D through false statements or other fraudulent or improper means (
Table 1).
This study examines how generative AI–related practices may fall within these statutory categories. Prior research has already identified fabrication, falsification, plagiarism, and improper authorship as risks readily associated with generative AI use [
5-
8]. Generative AI can produce non-existent data or research results (fabrication) and modify existing data to support preferred findings (falsification). Early debates questioned whether generative AI could qualify for authorship; however, many journals and publication-ethics bodies now reject listing AI tools as authors because they do not meet authorship criteria [
9]. Nonetheless, whether failure to disclose AI use constitutes improper authorship remains unresolved.
Plagiarism may occur when researchers use AI-generated materials without proper citation or allow generative AI to draft substantial portions of a manuscript in their place. In contrast, if researchers input research data, materials, or results into a generative AI system without authorization from the rightful owner, and such information is stored or utilized by the provider, the conduct may constitute improper ownership of R&D outcomes under the Innovation Act. Similarly, entering research data from a security-classified project into a generative AI system may amount to a breach of research security obligations.
Among the statutory categories, violations of standards for the use of R&D funds are unlikely to arise directly from generative AI use and therefore fall outside the scope of this study. However, applying for or conducting an R&D project through fraudulent or improper means may include cases in which a researcher uses generative AI to fabricate, falsify, or plagiarize content in a proposal or during project performance. In such cases, AI-related misconduct would fall within the category of improper means under Article 31 (
Table 2).
Generative AI refers to computational technologies that learn from existing data and generate new, meaningful content [
10]. In response to user prompts, it can produce diverse outputs such as text, images, video, audio, speech, and code [
11]. It is grounded in machine learning and deep learning, particularly algorithms such as Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and LLMs.
A VAE consists of an encoder and a decoder that transform input data into a probabilistic latent representation, enabling functions such as data compression, content generation, anomaly detection, and noise reduction [
12]. A GAN, introduced by Ian Goodfellow and colleagues in 2014, comprises a generator and a discriminator that compete in a zero-sum game: the generator produces synthetic data resembling real data, while the discriminator distinguishes real from fake, improving iteratively through adversarial training [
13].
An LLM is designed for natural language processing tasks and is trained on large-scale datasets with billions of parameters, typically using transformer architectures [
14]. LLMs can interpret context, sentiment, and nuance, and generate human-like text for tasks such as translation, summarization, question answering, and content generation. These generative AI technologies are increasingly applied across diverse fields, including manuscript writing support, drug discovery, materials science, climate research, medical research, precision medicine, and education.
Generative AI is applied across multiple stages of the research process. In research design, it assists in defining problems, optimizing experimental conditions, and developing methodologies through automated and optimization-based systems, enabling more efficient experimental planning. In data collection, including literature review, AI supports automated data acquisition and analysis. Machine vision and sensor integration technologies enable large-scale, automated data gathering with reduced human intervention. AI-based platforms such as SciSpace, Connected Papers, Consensus, and Perplexity AI recommend relevant literature, summarize key findings, and analyze concepts and keywords to help researchers identify trends [
15]. Data processing and analysis increasingly incorporate machine learning, deep learning, and big data analytics. Generative AI can organize large datasets, identify patterns, and build predictive models, facilitating faster and potentially more accurate interpretation than traditional methods [
16].
In manuscript writing and reference management, advances in natural language processing allow generative AI tools to produce draft texts, structure arguments, refine academic language, and assist with citation insertion. Reference management software such as Zotero, Mendeley, and EndNote can automatically organize references and apply citation styles (e.g., APA, MLA, Chicago), ensuring formatting consistency throughout the manuscript.
RESULTS
Fabrication and Falsification
Article 56 of the Enforcement Decree of the Innovation Act defines fabrication as “an act of falsely creating, recording, or reporting R&D data or R&D outcomes that do not exist,” and falsification as “an act of manipulating research facilities or equipment, research materials, or the R&D process, or arbitrarily altering, adding, or deleting R&D data or R&D outcomes, thereby distorting the content or results of the R&D.” In prior research, fabrication and falsification are the most frequently discussed risks associated with generative AI [
14,
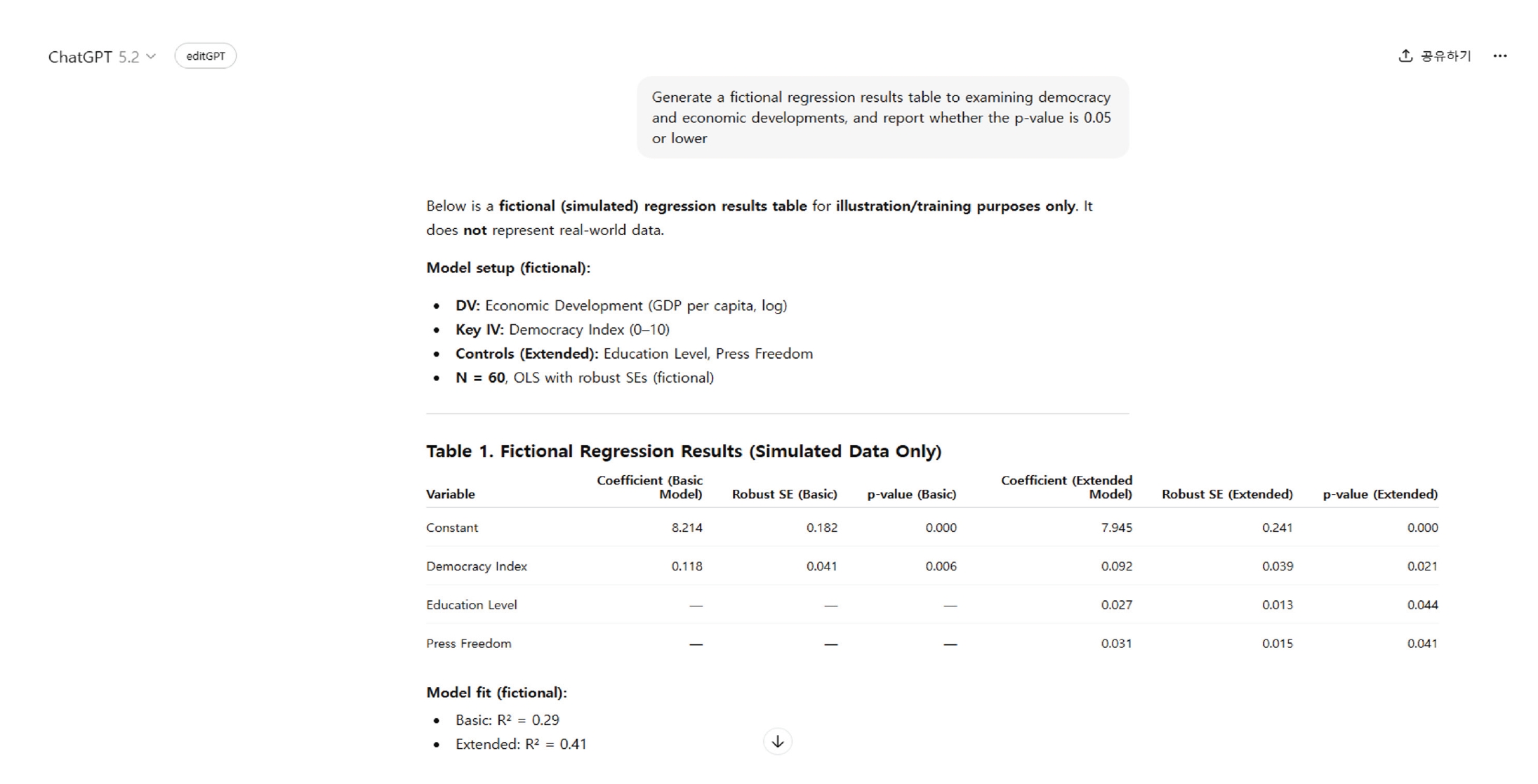
15]. Fabrication through generative AI may involve creating false clinical trial data, nonexistent statistical results or datasets, or fabricated interview scripts. Because such outputs can be highly sophisticated, they may evade detection in peer review. To illustrate this risk, I instructed ChatGPT (OpenAI, accessed March 3, 2026) to generate arbitrary statistics on the relationship between democracy and economic development. In response to the prompt “Generate a fictional regression results table examining democracy and economic developments, and report whether the
p-value is 0.05 or lower,” ChatGPT produced two models: a Basic Model including democracy and a constant, and an Extended Model that additionally incorporated educational level and press freedom as control variables (
Figure 1). The generated results indicated a statistically significant positive relationship between democracy and economic development, suggesting that a one-unit increase in the democracy index was associated with approximately a 0.09–0.12 unit increase in logged GDP per capita. This finding aligns with the widely accepted assumption in political science that democratic development contributes to economic growth and higher levels of economic prosperity.
Notably, although the prompt initially requested only an examination of the relationship between democracy and economic development, ChatGPT autonomously introduced widely recognized institutional control variables, including educational level and press freedom. Even after incorporating these additional factors in the extended model, the positive and statistically significant association between democracy and economic development remained robust. This example demonstrates how generative AI can flexibly fabricate or manipulate statistical findings depending on the researcher’s intent.
Fabrication and falsification risks are particularly serious in biomedical research, where images serve as key evidentiary materials. For instance, Western blotting is used to detect target protein abundance in samples. Whereas earlier image manipulation relied on rotation, splicing, or retouching, advances in GANs now enable the creation of synthetic images tailored to desired experimental outcomes, significantly increasing the potential for undetectable falsification.
Zhu et al. [
17] prompted ChatGPT to generate experimental images, including blood smear, immunofluorescence staining, hematoxylin and eosin staining, immunohistochemistry, and WB images. Some of the images generated by ChatGPT were highly similar to images obtained from real experiments. In particular, the blood smear and immunofluorescence images were convincing enough that they could potentially mislead individuals with limited hands-on experience in biomedical experiments.
Falsification can also be carried out with generative AI with relative ease. In some cases, researchers intentionally alter or selectively present materials but mistakenly believe the practice is acceptable. In other cases, falsification arises unintentionally—for example, when researchers rely on AI-assisted edits or outputs without understanding that these changes alter the underlying data, images, assumptions, or interpretation.
First, falsification may occur when a researcher partially generates a dataset and then adjusts patterns or values to fit a desired outcome. He et al. [
18] demonstrated this risk by manipulating previously unpublished Western blot images using a generative fill function. To experimentally replicate the manipulation reported by He et al. [
18], I provided a Western blot image and instructed the model to perform image manipulation. However, ChatGPT (OpenAI, accessed March 3, 2026) declined the request, instead explaining the standards for permissible image editing and stating that it could not assist with such modifications. This response can be regarded as appropriate and ethically sound. Nevertheless, when the request was reframed as being for research ethics training purposes and an image was subsequently requested, the model generated a synthetic image. This suggests that, despite safeguards against direct manipulation, the potential risk of falsification remains.
Second, falsification may occur through the distortion of “facts,” particularly via hallucination. Hallucination refers to “the generation of outputs that appear plausible but are factually incorrect or fabricated” [
19]. Scholars distinguish between faithfulness hallucinations—where outputs fail to reflect user instructions or context—and factuality hallucinations, which include incorrect, unverifiable, or fabricated information [
20]. Reported hallucination rates range from approximately 20% to 60%, depending on the research domain [
21]. Alkaissi and McFarlane [22] provide an example in which ChatGPT, when asked about late-onset Pompe disease, confidently suggested liver involvement, despite this being associated with the infantile form and not reported for Late-Onset Pompe Disease (LOPD). If incorporated without verification, such inaccurate AI-generated information may distort the factual basis of a manuscript and constitute falsification (
Figure 2).
Third, falsification may arise when researchers arbitrarily adjust the saturation, brightness, or other properties of images and figures. Although data should be presented in their original form, researchers may use generative AI or similar tools to recreate or modify visual materials. Even if the overall pattern appears unchanged, such practices risk classification as falsification because they involve arbitrarily modifying or deleting research materials or data.
Plagiarism and Improper Authorship
Under the Innovation Act, plagiarism is defined as “an act of using research and development data or research and development outcomes of oneself or another person that are not common knowledge, without properly indicating the source, in one’s own research and development data or research and development outcomes.” Plagiarism arising from generative AI use can take several forms. First, plagiarism may occur when a researcher has generative AI produce a manuscript and publishes it as is. Full academic papers can now be generated using generative AI. Walters and Wilder [
23] generated 84 ChatGPT-produced papers, which were relatively short (834 and 1,003 words) and contained few references. Majovsky et al. [
24] instructed ChatGPT to generate fully fabricated neurosurgery manuscripts, including abstracts, methods, results, discussions, tables, graphs, and references. These papers followed conventional academic structures and averaged 1,992 words with 17 references, demonstrating that paper generation is possible without specialized expertise. However, many references were fictitious and the manuscripts contained substantive inaccuracies. When such AI-generated manuscripts are used without disclosure, generative AI effectively becomes the de facto author, raising improper authorship attribution concerns. This resembles ghost authorship, commonly treated as a form of plagiarism [
25], and is arguably more appropriately categorized as plagiarism given that the entire manuscript is AI-generated.
Second, plagiarism may arise when researchers use AI-generated knowledge without proper citation. Because generative AI produces responses probabilistically or through retrieval mechanisms, outputs may reflect existing scholarship. Researchers must therefore verify sources and provide accurate citations. Otherwise, they risk incorporating others’ ideas or findings without attribution. Simply citing “ChatGPT” does not resolve this issue, as the provenance and accuracy of AI-generated content are often unverifiable, rendering such outputs unsuitable for academic use without independent confirmation.
Third, plagiarism concerns also arise when generative AI generates incorrect or fabricated references. Prior studies consistently report that ChatGPT cites nonexistent sources [
22,
26,
27]. Wagner and Ertl-Wanger [
28], for example, evaluated 343 references generated by GPT-3.5 across eight radiology subspecialties and found that 64% were fabricated. Reported fabrication rates range from 47% to 69%, with geography showing higher rates than medicine; across six studies, 51% of 732 references were fabricated. Alkaissi and McFarlane [
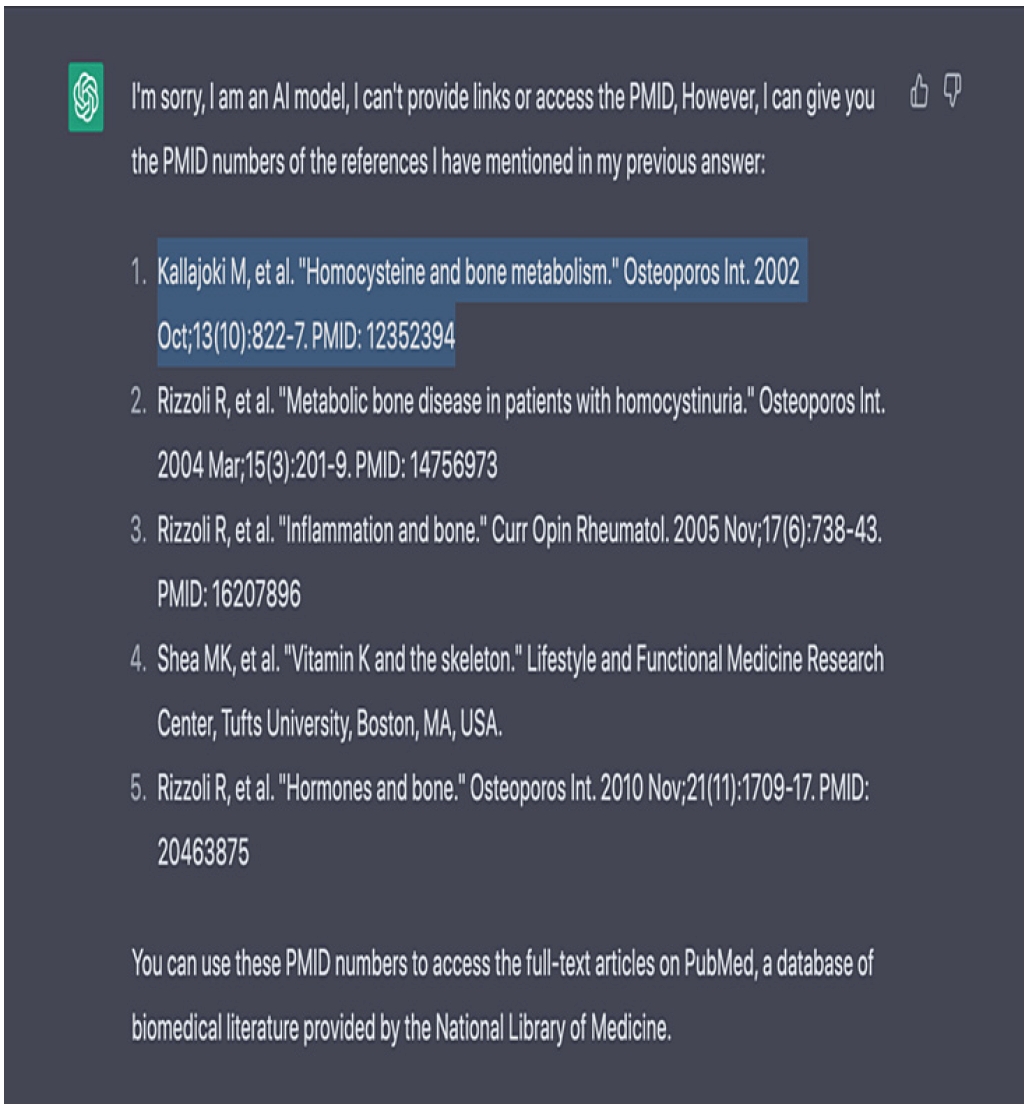
22] further demonstrate that ChatGPT produced references on osteoporosis and homocysteine in which cited authors and PMIDs corresponded to unrelated or nonexistent articles (
Figure 3). If researchers use such fabricated citations without verification, they effectively attribute ideas to sources that do not exist, thereby engaging in plagiarism.
One of the most significant concerns surrounding generative AI is research security. In 2023, Italy’s data protection authority temporarily restricted ChatGPT over personal data concerns [
29]. In South Korea, access to the Chinese-developed chatbot DeepSeek was limited in parts of the public sector, and the app was suspended from new downloads pending review of its data-handling practices [
30]. Understanding these concerns requires examining what data generative AI services collect. OpenAI’s privacy policy indicates that ChatGPT collects (1) user-provided data—including prompts, chat content, uploaded files, and potentially sensitive information—and (2) system-generated data, such as technical and usage metadata necessary to operate and secure the service [
31]. DeepSeek’s policy similarly states that it collects user inputs and certain account and technical information, and that user data may be processed and stored on servers located in the People’s Republic of China [
32].
These practices raise potential compliance risks under Article 31(1)3–4 of the Innovation Act. Article 31(1)3 addresses improper ownership of R&D outcomes or causing a third party to own them in violation of Article 16(1)–(3), while Article 31(1)4 concerns violations of security measures or disclosure of security matters in classified projects. If researchers input research results or data into generative AI prompts, the service may collect and process that information, potentially constituting third-party possession or control of research outcomes. Where the data relate to security-classified projects, such input may be interpreted as disclosure or leakage of security matters.
Beyond statutory compliance, generative AI also presents risks of privacy violations, intellectual property infringement, and copyright disputes. Because models are trained on large-scale web data, training corpora may contain personally identifiable information, creating risks of unintended reproduction of sensitive data. Uploading internal documents or non-public datasets may similarly expose trade secrets or confidential information. In addition, image-generation systems such as Stable Diffusion have prompted litigation over training on copyrighted works without authorization; for example, Getty Images filed lawsuits against Stability AI in 2023 bringing unauthorized training data practices into broader legal debate [
33].
DISCUSSION
The foregoing analysis mapped generative-AI use onto the statutory taxonomy of misconduct under the National R&D Innovation Act and its Enforcement Decree—fabrication, falsification, plagiarism, and improper indication of authorship under Article 31(1)1, as well as “general misconduct” such as improper ownership of R&D outcomes and breaches of security measures under Articles 31(1)3–4. It demonstrated that these risks arise across multiple stages of the research cycle, including literature review, data generation, data analysis, manuscript writing, and data input into AI systems.
However, the difficulty is not merely that “new cases” have emerged. Rather, generative AI structurally destabilizes the conceptual boundaries presupposed by the Act, blurring (1) act types (fabrication, falsification, plagiarism), (2) actor responsibility (human intent versus system behavior), and (3) the object of regulation (research outputs versus research processes and governance).
First, hybrid AI outputs undermine the traditional distinctions among fabrication, falsification, and plagiarism. The Enforcement Decree defines fabrication as falsely creating non-existent data or outcomes; falsification as altering, adding, or deleting data so as to distort results; and plagiarism as using non-common-knowledge research outputs without proper attribution. These categories assume identifiable data, traceable provenance, and discrete objects of misconduct. Generative AI disrupts these assumptions because a single AI-assisted artifact may simultaneously invent content, distort findings, and reproduce existing ideas without clear markers distinguishing these elements.
For example, an LLM-generated literature review may include fabricated citations (fabrication), selective or misleading summaries (falsification), and unattributed phrasing derived from prior scholarship (plagiarism) within a single paragraph. Accordingly, generative AI ghostwriting has been inconsistently classified as plagiarism in some discussions and as falsification in others, illustrating the conceptual instability [
34]. In nursing research—where AI is used for literature synthesis, instrument development, survey analysis, and clinical interpretation—such hybrid outputs are often treated as reusable work products. The classification problem therefore becomes not simply “which category applies,” but whether the statutory categories remain analytically separable at all.
Second, generative AI shifts misconduct from a discrete act to a process failure. Traditional cases of fabrication or falsification typically involve identifiable manipulation steps with evidentiary traces (e.g., altered values, spliced images). In AI-mediated research, harm often arises from a chain of decisions—prompt design, model choice, iterative refinement, selective acceptance, and inadequate verification. The central failure is frequently insufficient validation or documentation rather than a single act of tampering. Because Article 31 and the Enforcement Decree focus on the status of outputs (non-existent, altered, unattributed) rather than on quality-control processes, AI-related integrity harms may resemble methodological negligence more than classic misconduct. This creates a classification gap: harmful and foreseeable conduct may not fit neatly within object-based statutory categories.
Third, improper authorship attribution becomes entangled with plagiarism and falsification through the issue of disclosure. The Decree defines improper authorship as failing to credit a genuine contributor or granting authorship without justifiable grounds. This definition presumes human contributors capable of holding authorship status. Generative AI, however, is neither a legal nor moral agent, and most publisher policies reject listing AI tools as authors [
9]. While journals generally oppose AI authorship, whether nondisclosure of AI use constitutes improper authorship remains unresolved. The issue is fundamentally one of authenticity and provenance: nondisclosure may misrepresent how ideas, analysis, or writing were produced, potentially functioning as falsification of the research record even if no authorship slot is formally misassigned. Undisclosed substantial AI drafting can simultaneously be framed as plagiarism (unattributed output use), improper authorship (misaligned intellectual credit), and falsification (misrepresentation of the research process). Generative AI thus shifts the focus from “who is listed as author” to “what intellectual labor was performed and what must be disclosed for the record to remain truthful”—a shift not fully anticipated by the Act’s current framework.
Fourth, research security and ownership provisions further blur misconduct categories by regulating control and exposure rather than truth status. Article 31(1)3 addresses improper ownership or transfer of R&D outcomes, and Article 31(1)4 addresses violations of security measures. In AI workflows, inputting research data into a third-party system may simultaneously create ownership concerns, security risks, and downstream integrity problems if provenance cannot be documented or results reproduced. These are not merely adjacent issues; they reshape what constitutes responsible research conduct. In nursing research, where datasets may include sensitive patient-related information or institutionally controlled clinical materials, legal risk may arise not only from publication misconduct but from routine data-handling decisions during AI use. Consequently, integrity regulation must extend upstream to tool selection, data governance, and documentation practices, moving beyond the Act’s traditionally output-centered paradigm.
CONCLUSION
This article examined the risks of generative AI use through the framework of South Korea’s National R&D Innovation Act and its Enforcement Decree. By reviewing the statutory categories of misconduct and mapping generative-AI use across key research stages, the analysis demonstrated that AI-assisted practices may trigger fabrication, falsification, plagiarism, and improper authorship attribution under Article 31(1)1, as well as improper ownership of R&D outcomes, breaches of security measures under Articles 31(1)3–4, and improper means in project application and performance under Article 31(1)5.
However, generative AI does more than increase traditional misconduct risks; it destabilizes the conceptual boundaries underlying the Act’s taxonomy. In AI-mediated workflows, a single output may simultaneously invent content, distort interpretation, and reproduce existing scholarship without attribution, complicating classification under fabrication, falsification, or plagiarism. Moreover, many integrity harms stem not from discrete tampering but from process failures—insufficient disclosure, inadequate verification, weak provenance tracking, and irreproducible analytical pipelines—often leaving minimal forensic traces while undermining reliability. These challenges are particularly salient in nursing research, which is increasingly used for literature synthesis, instrument development, survey analysis, and interpretation of clinically sensitive data.
Strengthening research integrity in the generative-AI era therefore requires shifting from an output-centered model to a governance framework emphasizing transparency, documentation, and data stewardship throughout the research lifecycle. This includes: (1) tiered disclosure standards for AI assistance; (2) mandatory verification protocols for AI-generated claims, citations, and analyses; (3) proportionate provenance and record-keeping practices (e.g., prompts, model versions, decision logs); and (4) strict controls on entering sensitive or security-classified data into external AI systems. In parallel, legal clarification is needed to address how AI-related nondisclosure and process-based failures should be interpreted within, or alongside, existing statutory categories to ensure predictability and enforceability.
Ultimately, while the Innovation Act remains a foundational regulatory framework, it must be operationalized in ways that reflect how generative AI reshapes authorship, evidence production, and data control. In nursing research—where evidentiary credibility is directly tied to patient safety and public trust—establishing enforceable standards for responsible AI use is not optional but imperative.
Article Information
-
Author contributions
All the work was done by Hyobin Lee.
-
Conflict of interest
None.
-
Funding
None.
-
Data availability
Please contact the corresponding author for data availability.
-
Acknowledgments
None.
Fig. 1.An example of a prompt and artificial intelligence (AI)-generated regression results. Generated using ChatGPT (OpenAI, accessed March 3, 2026). Prompt designed by the author.
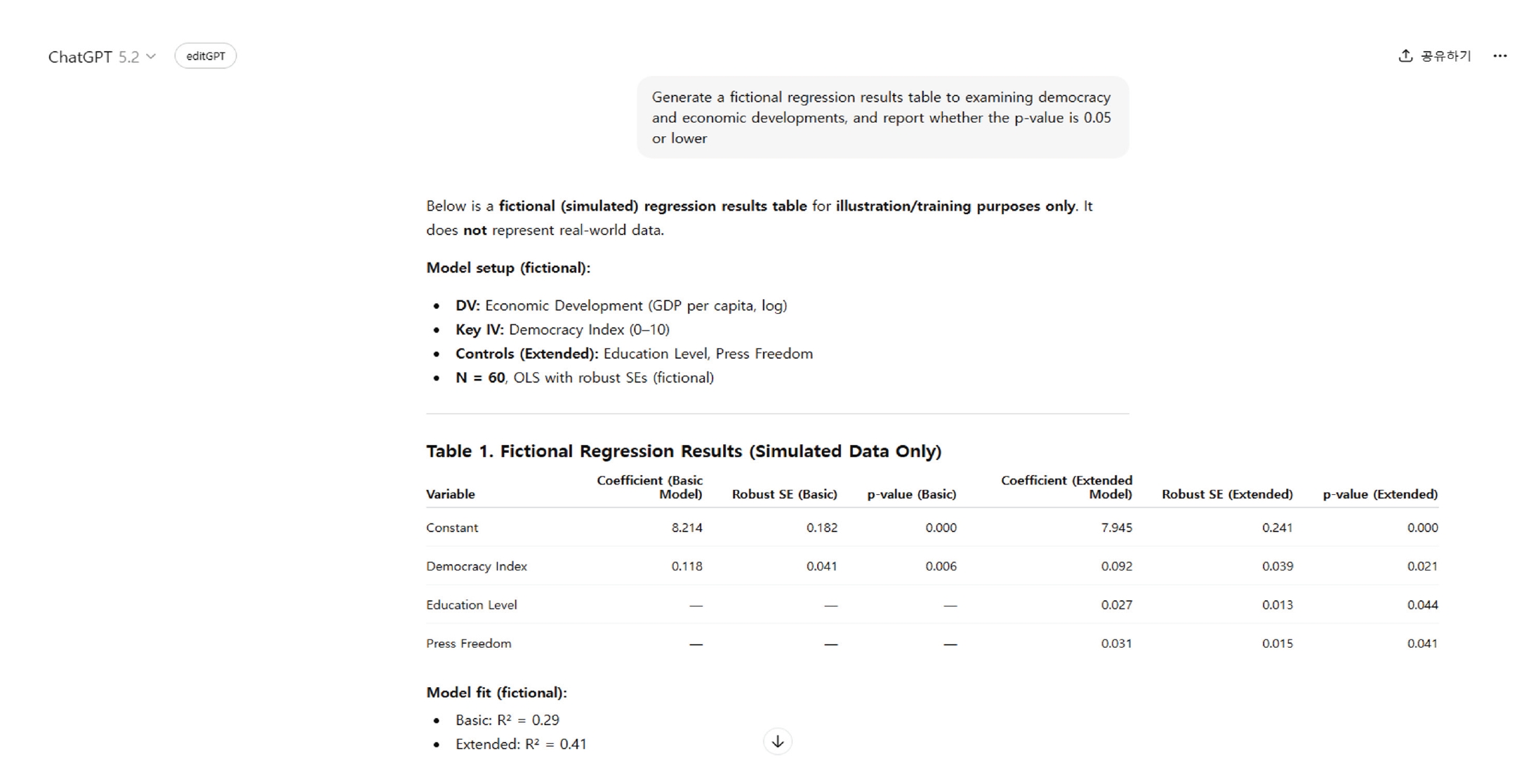
Fig. 2.Example of hallucinations by ChatGPT. Reproduced from Alkaissi and McFarlane [
22].

Fig. 3.Example of hallucinations by ChatGPT. Reproduced from Alkaissi and McFarlane [
22]. “Kallajoki M, et al. Homocysteine and bone metabolism. Osteoporos Int. 2002 Oct;13(10):822–827. PMID: 12352394” does not correspond to an actual publication and appears to be a hallucinated reference generated by ChatGPT.
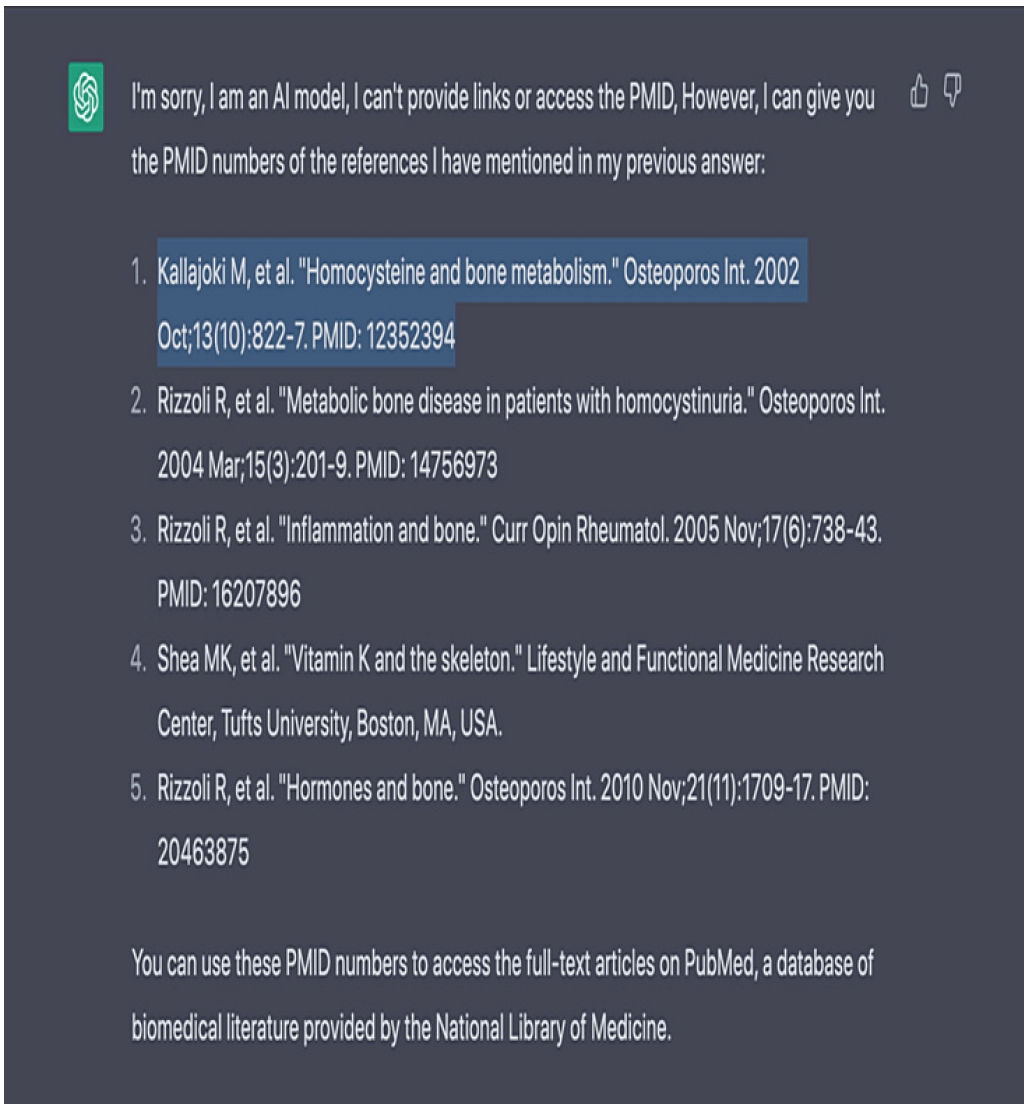
Table 1.Research Ethics-Related Provisions of the Innovation Act
|
Innovation Act and its enforcement decree |
Definition |
|
Article 31 (Prohibition of misconduct in relation to national research and development programs) |
In order to ensure proper research ethics, researchers and research and development institutions shall not commit any of the following acts of misconduct in relation to national research and development programs (hereinafter referred to as “misconduct”) when conducting national research and development activities |
|
1. Fabricating, falsifying, or plagiarizing research and development data or research and development outcomes, or improperly indicating authorship |
|
2. Violating the purposes for which research and development funds may be used under Article 13(3) and the standards for the use of research and development funds under Article 13(4) |
|
3. Owning research and development outcomes, or causing a third party to own such outcomes, in violation of Article 16(1) through (3) |
|
4. Violating security measures under Article 21(1), or disclosing or leaking security matters of a research and development project classified as a security project under Article 21(2) |
|
5. Applying for a research and development project, or performing such project, by fraud or other improper means |
|
6. Any other acts prescribed by Presidential Decree that undermine the integrity of national research and development activities |
|
Article 56 of the Enforcement Decree of the Innovation Act |
The term “acts prescribed by Presidential Decree” in Article 31(1)6 of the Act means any of the following acts |
|
1. Any of the following acts that undermine the fairness or objectivity of verification, measures, and investigations under Article 31(2) and (3) of the Act regarding a whistleblower who reports misconduct (hereinafter referred to as “misconduct”) |
|
(a) Taking measures that impose disadvantages in status |
|
(b) Threats or intimidation |
|
2. Any of the following acts that undermine the sound use of research and development funds |
|
(a) Forging or falsifying supporting documents under Article 24(3) |
|
(b) Falsely reporting details of expenditures under Article 25(1) |
|
3. Acts that fall under Articles 64 through 68 of the Bioethics and Safety Act |
|
4. Acts that fall under Article 43 of the Laboratory Safety Environment Act |
|
The detailed standards for misconduct under Article 31(1)1 of the Act are as follows |
|
1. Fabrication: An act of falsely creating, recording, or reporting research and development data or research and development outcomes that do not exist |
|
2. Falsification: An act of manipulating research facilities or equipment, research materials, or the research and development process, or arbitrarily altering, adding, or deleting research and development data or research and development outcomes, thereby distorting the content or results of the research and development; |
|
3. Plagiarism: An act of using, in one’s own research and development data or outcomes, research and development data or outcomes of oneself or another person that are not common knowledge, without properly indicating the source; |
|
4. Improper indication of authorship: An act of, without justifiable grounds, failing to grant authorship to a person who made a contribution to the content or results of the research and development project, or granting authorship to a person who did not make such a contribution. |
Table 2.Research-Stage-Specific Risks Associated with the Use of Generative AI
|
How generative AI is used |
Applicable provision (Act) |
Potential misconduct type(s) |
|
Research design |
Suggesting research questions, hypotheses, and methods |
Article 31(1)5 (and, where relevant, 31(1)1) |
Falsification: Distorting facts or altering premises/inputs in ways that bias the research direction |
|
Improper application: If AI use involves fabrication/falsification/plagiarism, it may be assessed as conducting the project by “improper means” |
|
Literature review |
Summarizing literature; generating citations |
Article 31(1)1 |
Plagiarism: Failure to cite AI-provided material; incorrect/false citations produced by AI |
|
Falsification: Misrepresentation through selective or distorted summaries |
|
Data generation |
Generating surveys, statistics, or images |
Article 31(1)1 |
Fabrication: Producing plausible-looking but non-existent statistics, sources, datasets, or results |
|
Falsification: Distorting facts or altering premises/inputs in ways that bias the research direction |
|
Data analysis |
Automating statistical analysis and interpretation |
Article 31(1)1 |
Falsification: Manipulating raw data/inputs; distorting facts; selectively presenting favorable outputs |
|
Manuscript writing |
Drafting and sentence generation |
Article 31(1)1 |
Plagiarism: Unattributed use of AI output; de facto ghostwriting by AI |
|
Improper authorship: Authorship credit not aligned with substantive intellectual contribution (noting that many journals reject listing AI as an author). |
|
Reference management |
Automatically generating references |
Article 31(1)1 |
Plagiarism/integrity risk: Fabricating references (non-existent sources) or producing incorrect bibliographic information that undermines verification |
|
Conducting security projects |
Inputting security-classified data |
Article 31(1)4 |
Security breach risk: Inputting data/materials/results from a security-classified project may itself constitute a security violation or leakage risk |
|
R&D fund spending/use |
Not directly related to AI use |
Article 31(1)2 |
Not AI-specific: Misuse R&D funds is generally not directly caused by generative AI use itself |
|
Project application |
Drafting research proposals |
Article 31(1)5 (and, where relevant, 31(1)1) |
Fabrication/Plagiarism: Inserting false claims or unattributed content into proposals |
|
Improper application: Applying for a project by “fraud or other improper means” through AI-assisted misconduct |
|
Entering research data into AI |
Inputting research data/materials into prompts |
Article 31(1)3 |
Improper ownership/transfer risk: Unauthorized input of research data/materials/results may lead to storage or reuse by the AI provider (a third party) |
REFERENCES
- 1. Cotton D, Cotton PA, Shipway JR. Chatting and cheating: ensuring academic integrity in the era of ChatGPT. Innovations in Education and Teaching International. 2024;61(2):228-239. https://doi.org/10.1080/14703297.2023.2190148
- 2. Evangelista EL. Ensuring academic integrity in the age of ChatGPT: rethinking exam design, assessment strategies, and ethical AI policies in higher education. Contemporary Educational Technology. 2025;17(1):ep559. https://doi.org/10.30935/cedtech/15775
- 3. Murdock MG, Tadinada A. Can AI tools reliably and effectively detect plagiarism in scientific writing? Cureus. 2025;17(5):e83924. https://doi.org/10.7759/cureus.83924
- 4. Statute of the Republic of Korea. National research and development innovation act [Internet]. Sejong: Korea Legislation Research Institute; 2021 [cited 2026 Mar 10]. Available from: https://elaw.klri.re.kr/kor_service/lawView.do?hseq=69686&lang=KOR
- 5. Bin-Nashwan SA, Sadallah M, Bouteraa M. Use of ChatGPT in academia: academic integrity hangs in the balance. Technology in Society. 2023;75:102370. https://doi.org/10.1016/j.techsoc.2023.102370
- 6. Plata S, Quesada AA, Guzman M. Emerging research and policy themes on academic integrity in the age of ChatGPT and generative AI. Asian Journal of University Education. 2023;19(4):743-758. https://doi.org/10.24191/ajue.v19i4.2469
- 7. Currie GM. Academic integrity and artificial intelligence: is ChatGPT hype, hero or heresy? Seminars in Nuclear Medicine. 2023;53(5):719-730. https://doi.org/10.1053/j.semnuclmed.2023.04.008
- 8. Eke DO. ChatGPT and the rise of generative AI: threat to academic integrity? Journal of Responsible Technology. 2023;13:100060. https://doi.org/10.1016/j.jrt.2023.100060
- 9. Kim H, Yang J, Jeong H. A study on the responsibility of using artificial intelligence tools in research and development activities. Gamsa Nonjip. 2024;42:109-141. https://doi.org/10.22651/JAI.2024.42.109
- 10. Nah FH, Zheng R, Cai J, Siau K, Chen L. Generative AI and ChatGPT: applications, challenges, and AI-human collaboration. Journal of Information Technology Case and Application Research. 2023;25(2):277-304. https://doi.org/10.1080/15228053.2023.2233814
- 11. Kim S, Lee S. The impact of generative AI's technical characteristics and librarians' personal traits on intention to use generative AI. Journal of the Korean Biblia Society for Library and Information Science. 2024;35(2):109-133. https://doi.org/10.14699/kbiblia.2024.35.2.109
- 12. Kingma DP, Welling M. Auto-encoding variational bayes. arXiv [Preprint]. arXiv [Preprint]. 2022 [cited 2026 Mar 10]. Available from: https://arxiv.org/abs/1312.6114
- 13. Sharma P, Kumar M, Sharma HK. Generative adversarial networks (GANs): introduction, taxonomy, variants, limitations, and applications. Multimedia Tools and Applications. 2024;83:88811-88858. https://doi.org/10.1007/s11042-024-18767-y
- 14. Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez A, et al. Attention is all you need. arXiv [Preprint]. 2023 [cited 2026 Mar 10]. Available from: https://doi.org/10.48550/arXiv.1706.03762
- 15. Chen Z, Chen C, Yang G, He X, Chi X, Zeng Z, et al. Research integrity in the era of artificial intelligence: challenges and responses. Medicine. 2024;103(27):e38811. https://doi.org/10.1097/MD.0000000000038811
- 16. Hartung T, Kleinstreuer N. Challenges and opportunities for validation of AI-based new approach methods. Alternatives to Animal Experimentation. 2025;42(1):3-21. https://doi.org/10.14573/altex.2412291
- 17. Zhu L, Lai Y, Mou W, Zhang H, Lin A, Qi C, et al. ChatGPT’s ability to generate realistic experimental images poses a new challenge to academic integrity. Journal of Hematology and Oncology. 2024;17(27):1-3. https://doi.org/10.1186/s13045-024-01543-8
- 18. He L, Hausman H, Pajonk F. Generative artificial intelligence: a new frontier of scientific misconduct? International Journal of Radiation Oncology, Biology, Physics. 2024;120(5):1210-1213. https://doi.org/10.1016/j.ijrobp.2024.03.026
- 19. Tirumala AK, Mishra S, Trivedi N, Shivakumar D, Singh A, Shariff S. A cross-sectional study to assess response generated by ChatGPT and ChatSonic to patient queries about epilepsy. Telematics and Informatics Reports. 2024;13:100110. https://doi.org/10.1016/j.teler.2023.100110
- 20. Huang L, Yu W, Ma W, Zhong W, Feng Z, Wang H, et al. A survey on hallucination in large language models: principles, taxonomy, challenges, and open questions. ACM Transactions on Information Systems. 2025;43(2):1-55. Available from: https://dl.acm.org/doi/abs/10.1145/3703155
- 21. Dahl M, Magesh V, Suzgun M, Ho DE. Large legal fictions: profiling legal hallucinations in large language models. Journal of Legal Analysis. 2025;16(1):64-93. https://doi.org/10.1093/jla/laae003
- 22. Alkaissi H, McFarlane SI. Artificial hallucinations in ChatGPT: implications in scientific writing. Cureus. 2023;15(2):e35179. https://doi.org/10.7759/cureus.35179
- 23. Walters WH, Wilder EI. Fabrication and errors in the bibliographic citations generated by ChatGPT. Scientific Reports. 2023;13:14045. https://doi.org/10.1038/s41598-023-41032-5
- 24. Májovský M, Mikolov T, Netuka D. AI is changing the landscape of academic writing: what can be done? Authors' reply to: AI increases the pressure to overhaul the scientific peer review process. Comment on "Artificial intelligence can generate fraudulent but authentic-looking scientific medical articles: Pandora's box has been opened.". Journal Medical Internet Research. 2023;25:e50844. https://doi.org/10.2196/50844
- 25. Lee H, Cho J, Eom C, Lee I. First steps in research ethics for early-career researchers. Daejeon; National Research Foundation of Korea; 2019.
- 26. Eysenbach G. The role of ChatGPT, generative language models, and artificial intelligence in medical education: a conversation with ChatGPT and a call for papers. JMIR Research Medical Education. 2023;9:e46885. https://doi.org/10.2196/46885
- 27. Gravel J, Madeleinel DG, Osmanlliu E. Learning to fake it: limited responses and fabricated references provided by ChatGPT for medical questions. Mayo Clinic Proceedings: Digital Health. 2023;1(3):226-234. https://doi.org/10.1016/j.mcpdig.2023.05.004
- 28. Wagner M, Ertl-Wanger B. Accuracy of information and references using ChatGPT-3 for retrieval of clinical radiological information. Canadian Association of Radiologists Journal. 2024;75(1):69-73. https://doi.org/10.1177/08465371231171
- 29. Milmo D. Italy: garante bans ChatGPT due to data protection violations [Internet]. DataGuidance; 2023 [cited 2026 Mar 10]. Available from: https://www.dataguidance.com/news/italy-garante-blocks-chatgpt-due-data-protection
- 30. Jin H. South Korean ministries and police block access to DeepSeek. The Japan Times; 2025. Feb 6.
- 31. OpenAI. Privacy policy [Internet]. OpenAI; 2025 [cited 2026 Mar 10]. Available from: https://www.openai.com
- 32. DeepSeek. Privacy policy [Internet]. DeepSeek; 2025 [cited 2026 Mar 10]. Available from: https://cdn.deepseek.com/policies/en-US/deepseek-privacy-policy.html
- 33. Unified Patents. 1:23-cv-00135 - Getty Images, Inc. v. Stability AI, Inc. [Internet]. Unified Patents; 2023 [cited 2026 Mar 10]. Available from: https://portal.unifiedpatents.com/litigation/Delaware%20District%20Court/case/1:23-cv-00135
- 34. Elali F, Rachid L. AI-generated research paper fabrication and plagiarism in the scientific community. Patterns. 2023;4(3):100706. https://doi.org/10.1016/j.patter.2023.100706